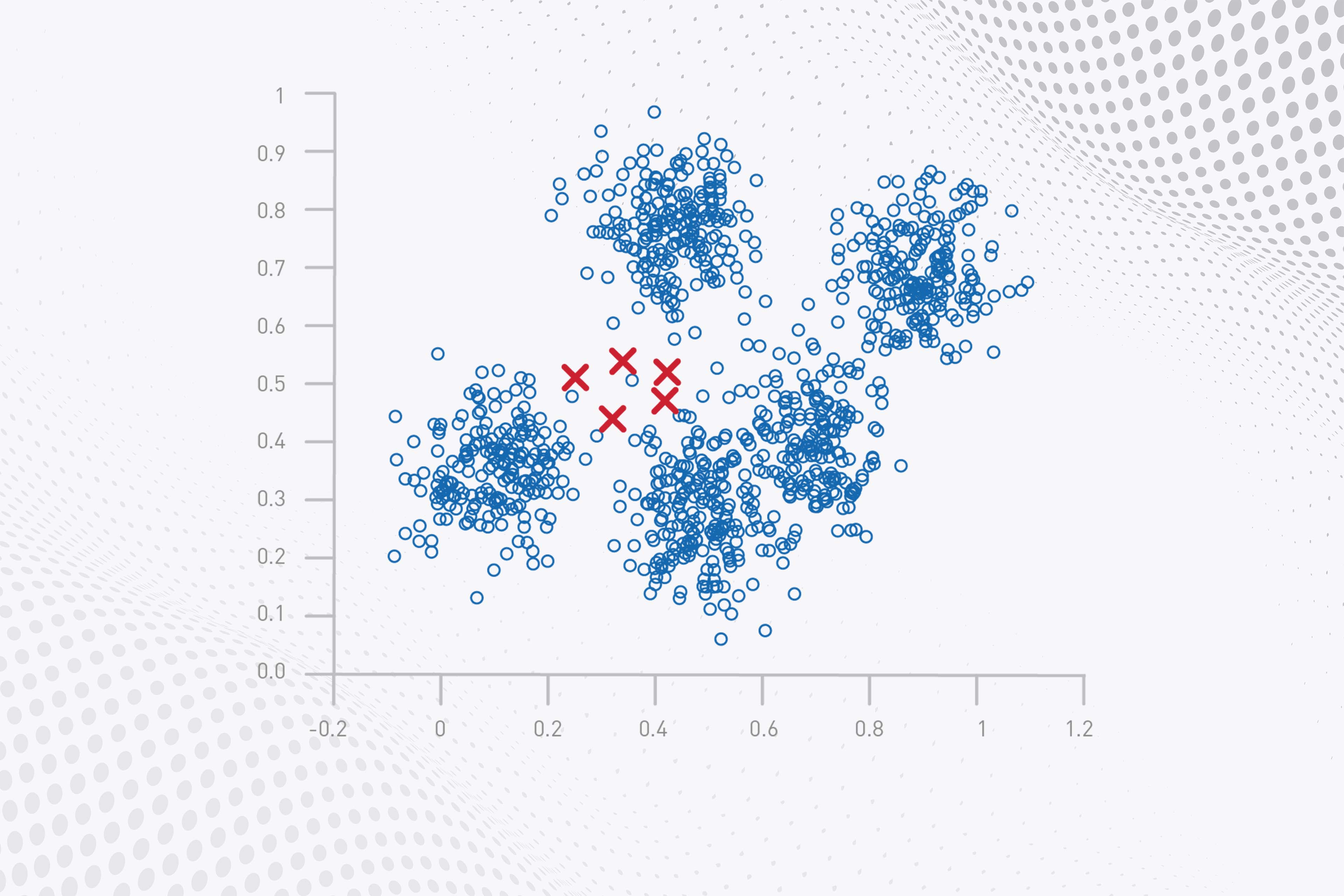

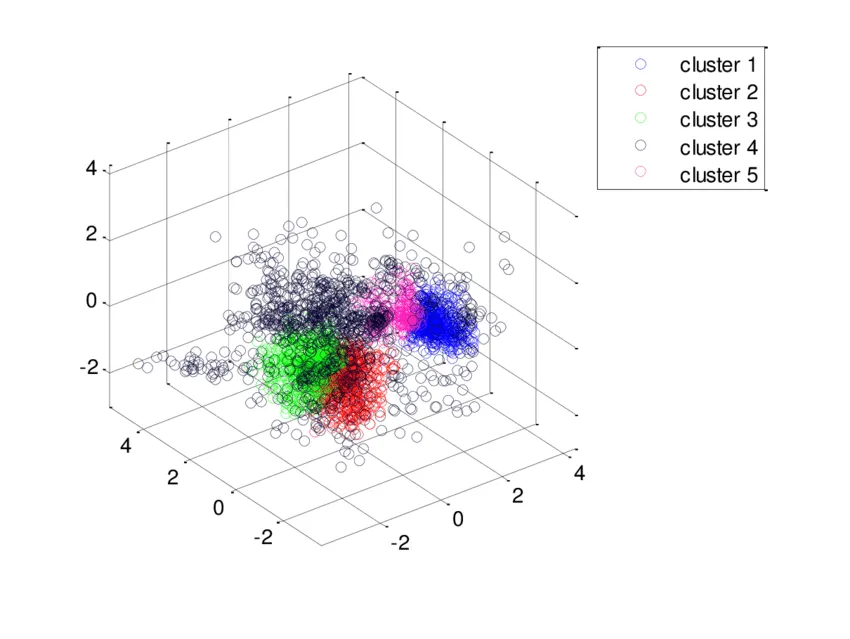
K-ortalama kümeleme ya da K-means kümeleme (K-means clustering) yöntemi “n”adet veri nesnesinden oluşan bir veri kümesini giriş parametresi olarak verilen K adet kümeye bölme işlemidir.
Amaç, gerçekleştirilen bölümleme işlemi sonunda elde edilen kümelerin, küme içi benzerliklerinin maksimum ve kümeler arası benzerliklerinin ise minimum olmasını sağlayacak şekilde gruplamaktır.
K-means en sık kullanılan gruplama(kümeleme) algoritmalarındandır. Büyük ölçekli verileri hızlı ve etkin şekilde kümeleyebilir. “K” algoritmaya başlamadan önce ihtiyaç duyulan sabit küme sayısını ifade etmektedir. 
Tekrarlı bölümleyici yapısı ile K-means algoritması, her verinin ait olduğu kümeye olan uzaklıkları toplamını küçültmektedir. K-means algoritması karesel hatayı en küçük yapacak olan K adet kümeyi tespit etmeye çalışmaktadır.
K-means algoritması nasıl çalışır?
K-means algoritmasının çalışma mekanizmasına göre öncelikle her kümenin merkez noktasını veya ortalamasını temsil etmek üzere K adet nesne rastgele seçilir.
Algoritma temel olarak 4 aşamadan oluşur:
- Küme merkezlerinin belirlenmesi
- Merkez dışındaki verilerin mesafelerine göre kümelendirilmesi
- Yapılan kümelendirmeye göre yeni merkezlerin belirlenmesi (veya eski merkezlerin yeni merkeze kaydırılması)
- Kararlı hale (stable state) gelinene kadar 2. ve 3. adımların tekrarlanması.
Teori kısmını aktardığımıza göre aşağıdaki bağlantıya tıklayarak kaggle ve github daki kodlama ve çalışmaları kendi notebooklarınızda deneyebilirsiniz.
kaggle: https://www.kaggle.com/serapgr/k-means-segmentation
Github: https://github.com/serapgur
** Yazı içeriği konusunda Wikipedia dan destek alındı.